

In today’s data-driven world, businesses are constantly looking for ways to streamline their operations and reduce costs. One way to achieve these goals is through document data extraction, the process of automatically extracting data from unstructured documents like invoices, receipts, and contracts.
Whether you’re new to document data extraction or looking to make business processes or improve your existing processes, this FAQ will provide valuable insights and information.
What Is Document Data Extraction?
Document data extraction is the process of automatically extracting data from unstructured documents like invoices, receipts, and contracts using software. The software uses algorithms to identify and extract key pieces of information, such as the date, amount, and vendor, and convert them into a structured format. This allows businesses to reduce the time and cost associated with manual data entry, as well as minimize the risk of errors and inconsistencies.

Document data extraction is commonly used in industries like finance, healthcare, and logistics to process large volumes of documents quickly and accurately. With modern machine learning algorithms, accuracy rates of over 90% are achievable, making the document processing and data extraction a valuable tool for businesses looking to improve their efficiency and productivity.
Why Is Data Extraction Important?
Data extraction is important because it enables businesses to unlock valuable insights and make informed decisions. By extracting data from various sources, such as databases, websites, and documents, businesses can analyze trends, monitor performance, and identify areas for improvement.
Data extraction also helps businesses reduce the time and cost associated with manual data entry, which can be error-prone and time-consuming. With automated data extraction tools, businesses can process large volumes of data quickly and accurately, freeing up resources for other important tasks.
What Is The Purpose Of Data Extraction?
The purpose of data extraction is to transform data from its original source into a more useful and structured format. This allows businesses to analyze, interpret, and use the data for a variety of purposes, such as reporting, decision-making, and forecasting.

Data extraction involves identifying and extracting relevant data from various sources, such as databases, websites, and documents, and converting it into a format that can be easily analyzed and used. This process can be automated using data extraction tools, which can save businesses time and resources.
What Are The Use Cases For Automatic Data Extraction?

Automatic data extraction can be used in a variety of industries and applications. In finance, it can be used to extract data from financial statements, accounts payable invoices, and receipts. In healthcare, it can be used to extract data from medical records and insurance claims. In logistics, it can be used to extract data from shipping documents and customs declarations. Automatic data extraction can also be used for sentiment analysis, social media monitoring, and web scraping. Essentially, any application that involves processing large volumes of unstructured data can benefit from automatic data extraction.
What Are The Limitations Of OCR?
OCR (Optical Character Recognition) is a technology used in document data extraction to convert unstructured text into a machine-readable format. However, OCR has some limitations. First, OCR accuracy depends on the quality of the input and document types. Poor quality scans or images can lead to errors in character recognition.

Second, OCR is less accurate for handwriting and non-standard fonts. Third, OCR may struggle with formatting and layout issues, such as columns, tables, and images. Finally, OCR requires significant computing resources, which can be a limitation for some applications. Despite these limitations, OCR remains an important technology for document data extraction and can achieve high accuracy rates with proper setup and optimization.
What Are The Alternatives To Automatic Data Extraction?
Automatic data extraction is a popular method for quickly and accurately extracting information from documents. However, there are several alternatives to automatic data extraction that businesses may consider depending on their needs and resources.
Manual data entry is one such alternative, but it can be slow, error-prone, and expensive. Outsourcing data extraction to a third-party service is another option, but it may not provide the level of control and customization that businesses require.

Developing a custom software solution for data extraction is another option, but it can be time-consuming and require a high level of expertise.
Additionally, pre-built software solutions may offer some level of automation, but may not be as flexible or customizable as building a custom solution. The best alternative to automate data extraction will depend on the specific needs and resources of the business, as well as the complexity of the data extraction task at hand.
Why Is It Worth Using A Document Database?
Document databases offer several advantages over traditional relational databases when it comes to storing unstructured data, such as documents and images. Unlike relational databases, document databases are designed to store data in a flexible, non-tabular format, making it easier to store and retrieve unstructured data. This can help businesses save time and resources when searching for specific information.

Document databases are also highly scalable and can handle large volumes of data without sacrificing performance. Additionally, document databases can be integrated with other technologies, like machine learning and natural language processing, to automate tasks and improve efficiency.
What Are The 3 Data Extraction Methods?
Manual Data Extraction
Manual data extraction involves the process of manually copying data from a source document and entering it into a destination system. This method based data extraction is often time-consuming, labor-intensive, and prone to errors, making it unsuitable for large-scale projects. However, it may be necessary for small-scale projects or in situations where the data is not easily machine-readable.
Semi-automatic Data Extraction
Semi-automatic data extraction involves the use of software tools to assist with the extraction process. This can include optical character recognition technology, which can scan and digitize text from physical documents, or natural language processing algorithms, which can extract structured data from unstructured text.
While this semi structured data, method is faster and more accurate than manual extraction, it still requires some human intervention, making it less efficient than fully automatic extraction methods.
Automatic Data Extraction
Automatic data extraction is a fully automated method of extracting data from structured documents or semi-structured sources, such as databases or XML files. It involves using specialized software tools to extract data, making the process much faster and more accurate than manual or semi-automatic methods. Automatic extraction is ideal for large-scale data extraction projects and can save businesses both time and money.
What Are The Steps Of Data Extraction?
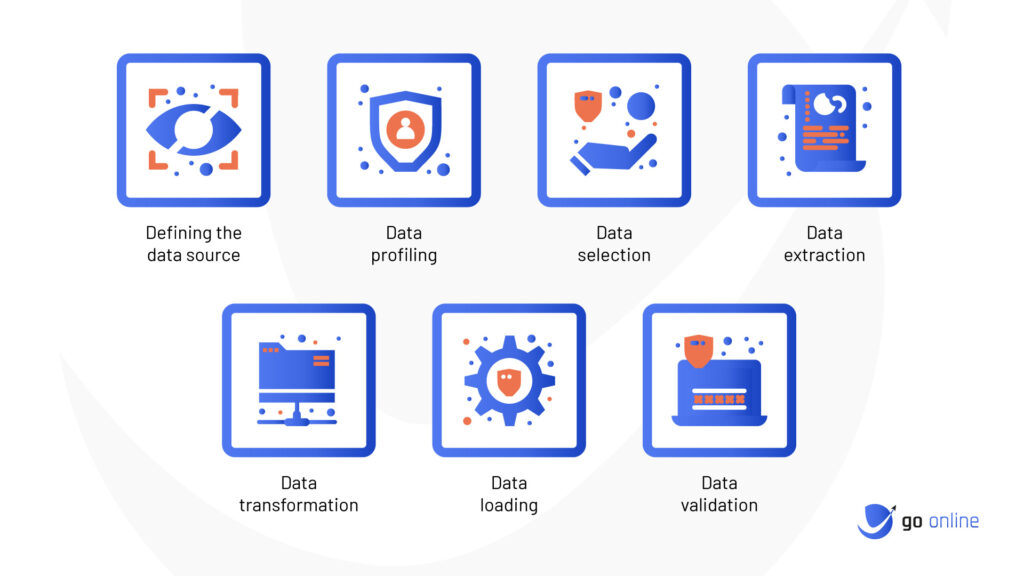
Defining The Data Source
This involves identifying the data sources from which data needs to be extracted. Data sources can include databases, files, websites, or other digital or physical sources. Defining the data source is a critical first step automated web data extraction, as it sets the foundation for the entire data extraction process.
Data Profiling
Data profiling is the process of analyzing the data sources to understand their structure and characteristics. This step in data mining is important as it helps to identify any data quality issues, such as inconsistencies or missing data, that may impact the accuracy and completeness of the extracted data.
Data Selection
In this step, the data that needs to be extracted is selected based on specific criteria, such as date ranges, file types, or specific keywords. This step involves developing queries or rules to extract the desired data from the identified data sources.
Data Extraction
This is the actual process of extracting data from the source(s) using the chosen data extraction method. This step can involve a variety of techniques, ranging from manual extraction to fully automated extraction using specialized software tools.
Data Transformation
After extraction, the data may need to be transformed to ensure consistency and compatibility with the destination system. This can include converting data formats, cleaning and standardizing data, or mapping data to match the destination system’s schema.
Data Loading
The extracted and transformed data is loaded into the destination system, such as a database or data warehouse. This step involves configuring the destination data storage or system to accept the extracted data and mapping the data to the destination system’s schema.
Data Validation
The extracted data is validated to ensure that it was extracted correctly and is accurate and complete. This step involves comparing the extracted data to the source data and identifying and resolving any discrepancies. Data validation is a critical step as it ensures the quality and reliability of the extracted data.
Can Data Extraction Be Automated?
Yes, data extraction can be automated using specialized software tools and techniques. Automated data extraction involves using software to automatically extract data from a variety of sources, such as databases, websites, or files, without requiring manual intervention. This approach can save a significant amount of time and effort, as well as reduce the risk of errors that may occur during manual extraction.

Automated data extraction tools often use machine learning and artificial intelligence algorithms to identify and extract relevant data from unstructured sources, such as text or images. However, it’s important to note that not all data extraction tasks can be fully automated, and some level of manual intervention may still be required for certain complex or specialized data extraction platform tasks.
What Software Is Used For Data Extraction?
There are a variety of software tools that can be used for data extraction, ranging from specialized tools designed for specific types of data extraction tasks to more general-purpose tools that can be used for a wide range of data extraction tasks.
Some popular software tools for data extraction include web scraping tools such as BeautifulSoup and Scrapy, database extraction tools like Talend, and OCR software like ABBYY FlexiCapture.

Other tools may be designed for specific types of data extraction tasks, such as email extraction tools or social media scraping tools. When selecting a software tool for data extraction, it’s important to consider factors such as the type and complexity of the data to be extracted, the scalability and flexibility of the data extraction tool, and the level of technical expertise required to use the tool effectively.
What Is The Performance Of Data Extraction Solutions?
The performance of data extraction solutions can vary widely depending on a variety of factors, including the complexity and volume of data to be extracted, the accuracy and precision required for the extracted data, and the quality of the source data. In general, automated data extraction solutions can offer significant benefits in terms of efficiency, speed, and accuracy compared to manual extraction methods.

However, the performance of these solutions can also be impacted by factors such as the quality of the software used, the complexity of the extraction process, and the level of expertise of the personnel involved in the the automating data extraction process. Additionally, the performance of data extraction solutions may also depend on the specific use case, with some tasks requiring more specialized or customized solutions in order to achieve optimal results.
How To Choose An Automated Data Extraction Solution That Syncs With Your Business Needs?
When choosing an automated data extraction solution, it is important to carefully evaluate your business needs and requirements in order to find a solution that can effectively meet those needs.
One key factor to consider is the volume and complexity of the data to be extracted, as well as the level of accuracy and precision required for the extracted data.
Additionally, it may be important to consider factors such as the ease of use and integration with existing systems, as well as the level of support and customization available from the software vendor. Other important factors may include the cost and scalability of the solution, as well as the level of security and compliance offered by the software.
Which OCR Can Be Used To Extract Document Understanding Data?
There are several Optical Character Recognition tools available in the market that can be used to extract document understanding data. Some of the most popular OCR software include Tesseract, Abbyy FineReader, Google Cloud Vision, Microsoft OCR, and Adobe Acrobat Pro DC. These OCR tools are designed to recognize and extract text from various types of documents, including scanned images, PDF files, and digital photos. In addition to text extraction, some OCR tools also offer advanced features such as handwriting recognition and language detection.
When selecting an OCR tool for document understanding data extraction, it is important to consider factors such as the accuracy and reliability of the software, as well as its compatibility with your existing systems and workflows.









 Like
Like
















