

In the digital age, businesses are inundated with an overwhelming amount of unstructured data contained within documents. Traditional methods of document handling and processing often lead to inefficiencies, errors, and wasted resources. However, there is a transformative solution on the horizon: Intelligent Document Recognition. From automating data extraction to enhancing document searchability and enabling seamless integration with other systems, IDR empowers organizations to unlock the true value of their unstructured data.
Join us on this enlightening journey as we delve into the realm of Intelligent Document Recognition and discover how it can empower organizations to streamline operations, boost productivity, and drive innovation in the digital era.
What is Intelligent Document Recognition?

Intelligent Document Recognition (IDR) is a sophisticated technology that revolutionizes the way organizations process and extract information from unstructured documents. With IDR, organizations can automatically classify, extract, and interpret data from various document types, including invoices, contracts, forms, and more.
Using a combination of artificial intelligence, machine learning, and optical character recognition techniques, IDR eliminates the need for manual data entry and tedious document handling processes. It analyzes the content of documents, identifies key data points, and converts them into structured and usable information.
Intelligent Document Recognition not only improves efficiency and accuracy in document processing but also enables organizations to gain valuable insights from their data, make informed decisions, and accelerate business processes.
How Does the ICR Work?
Intelligent Character Recognition (ICR) is a cutting-edge technology that enables the automated extraction and interpretation of handwritten or printed text from various documents. It uses a combination of advanced optical character recognition (OCR) techniques, pattern recognition algorithms, and machine learning models to accurately recognize and convert scanned or digital images of characters into editable and searchable text.

The process begins with the preprocessing of the document image, where it is enhanced and segmented into individual characters or words. The ICR system then applies advanced algorithms to analyze the shape, structure, and context of the characters, leveraging extensive training on a diverse dataset to identify and interpret the text accurately.
By harnessing the power of ICR, organizations can significantly reduce manual data entry efforts, improve accuracy in capturing handwritten information, and expedite document processing.
What Impact Does it Have on Business?
In the digital age, businesses are inundated with an overwhelming amount of unstructured data contained within documents. Traditional methods of document handling and processing often lead to inefficiencies, errors, and wasted resources. However, there is a transformative solution on the horizon: Intelligent Document Recognition.
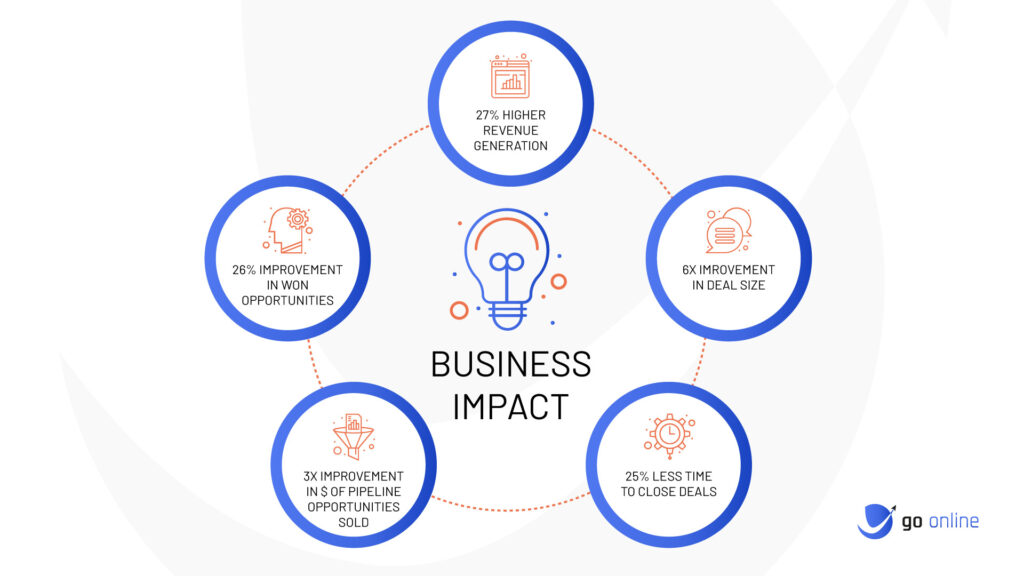
By harnessing the power of artificial intelligence, machine learning, and optical character recognition, IDR revolutionizes the way businesses handle, interpret, and utilize their documents. From automating data extraction to enhancing document searchability and enabling seamless integration with other systems, IDR empowers organizations to unlock the true value of their unstructured data.
What Are the Benefits of ICR?
Intelligent Character Recognition offers a myriad of benefits that significantly impact businesses. First and foremost, ICR automates the time-consuming and error-prone task of manual data entry, saving organizations valuable time and resources. By accurately extracting and digitizing text from various documents, ICR enhances data accuracy and reliability, leading to improved decision-making and insights.
Furthermore, ICR improves operational efficiency by streamlining document processing workflows, reducing bottlenecks, and accelerating business processes. With the ability to recognize both printed and handwritten text, ICR expands the scope of data capture, unlocking the value of unstructured data and enabling businesses to derive meaningful information from handwritten documents.
What is the Difference Between OCR and ICR?
OCR (Optical Character Recognition) and ICR (Intelligent Character Recognition) are both technologies used for automated data extraction from documents, but they differ in their capabilities and applications. OCR focuses on extracting printed or typewritten text from scanned or digital documents and converting it into editable and searchable text. It excels at recognizing standard fonts and structured documents such as invoices, receipts, and forms.
On the other hand, ICR takes the recognition process a step further by being able to interpret and extract handwritten or cursive text from documents. It utilizes advanced algorithms and machine learning techniques to recognize and convert handwritten characters into digital text. ICR is commonly used in scenarios where documents contain a mix of printed and handwritten information, such as surveys, applications, or handwritten forms.
While OCR is suitable for extracting printed text accurately, ICR extends the capabilities to handle both printed and handwritten content, enabling more comprehensive data extraction and analysis.
How to Choose Intelligent Document Processing Software?

Choosing the right intelligent document processing software is crucial for organizations aiming to streamline their document-related workflows and maximize efficiency. To make an informed decision, several factors should be considered.
Firstly, assessing the software’s capabilities is essential. Look for features such as advanced optical character recognition, intelligent data extraction, document classification, and automated workflow management.
Additionally, the software should be flexible and adaptable to different document types and formats. Integration capabilities with existing systems and applications, such as customer relationship management or enterprise resource planning systems, are also crucial for seamless data exchange.
How Quickly Can Intelligent Document Processing be Implemented?
The implementation timeline for intelligent document processing can vary depending on various factors. It primarily depends on the complexity and scale of the organization’s document management needs, as well as the specific software solution chosen. Smaller organizations with straightforward requirements may be able to implement intelligent document processing relatively quickly, often within a matter of weeks.
They can leverage cloud-based solutions with user-friendly interfaces that require minimal customization.
However, for larger organizations with more intricate document workflows and integration requirements, the implementation timeline may be longer. It involves activities such as data mapping, system integration, customization, and user training.
What Problems Can We Encounter While Implementing ICR?
While implementing Intelligent Character Recognition technology, organizations may encounter certain challenges. One common problem is the quality of the input documents. Poor document quality, such as low-resolution scans or illegible handwriting, can hinder the accuracy of the recognition process. It is crucial to ensure that documents are properly scanned and that the software is capable of handling variations in document quality.
Another challenge is the complexity of document formats and layouts. Different document types and structures may require customized configurations and training to accurately extract and interpret the relevant information. Additionally, integrating ICR software with existing systems and workflows can pose technical difficulties. It is important to ensure seamless data exchange and compatibility with other applications to avoid disruptions to existing processes.
Use Cases For Intelligent Document Processing

Intelligent document processing (IDP) holds tremendous potential for transforming various industries by automating and streamlining document-related tasks. One prominent use case is in the financial sector, where IDP can revolutionize invoice processing, purchase orders, and loan applications, reducing manual errors and speeding up the approval process. In healthcare, IDP can simplify patient record management, insurance claims processing, and medical coding, enhancing data accuracy and improving patient care.
For legal firms, IDP can automate contract review, legal research, and processing documents and case management, enabling lawyers to focus on higher-value tasks. In the retail industry, IDP can facilitate efficient inventory management, supplier invoices, and customer order processing. Furthermore, government agencies can leverage IDP for citizen document verification, permit processing, and compliance monitoring.
Summary
IDR, driven by artificial intelligence and machine learning, revolutionizes document handling and processing by offering automation, accuracy, and increased efficiency. It enables organizations to unleash the true potential of unstructured data through automated data extraction, improved document search capabilities, and seamless integration with other systems.
The benefits of IDR are significant, including time and resource savings, enhanced data accuracy, streamlined workflows, and improved compliance. The features of IDR, such as advanced OCR, document classification, and intelligent data extraction, empower organizations to effectively manage and scan documents and extract insights from their document repositories.









 Like
Like

















